This blog post will cover how to access the object store on ZFS to create buckets and upload files. For S3, I am using Cloudberry, which I downloaded here. For OCI, I am using the OCI cli tool.

S3 access to ZFS
This is the easiest, since the S3 object store on ZFS is an S3 compatible interface.
In cloudberry add a new account and use the following for input.
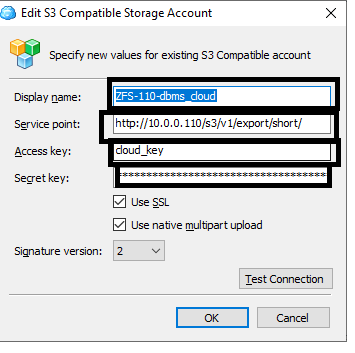
Note that you need to enter the 4 fields above.
- Display Name -- What you want to call the new account entry
- Service Point -- This is the ZFS interface for S3 in the form of
HTTP://{the IP of the ZFS}/s3/v1/{share name}
- Access Key -- This is the name you gave the S3 access key, when you added it to the ZFS
- Secret Key -- This is the long string of characters that was returned by ZFS when you created the key.
That's it ! You can now use cloudberry to create buckets, upload files, sync object stores etc.
OCI access to ZFS
Install the CLI
Like the Oracle cloud, there is currently (as of me writing the blog post), no GUI tool like cloudberry that will connect to an OCI object store. When connecting to the Oracle cloud, you can access the OCI object store through the S3 interface, but this is not possible on ZFS. Both the OCI and S3 object store are independent and cannot access buckets etc. in the other object store.
In order to access ZFS through OCI we start with downloading the OCI cli tool. Documentation on how do this can be found here.
In my install, I took the easy route (and since I had a Ubuntu client with root access to play with). I installed it directly using "sudo pip install oci-cli"
Create a config file.
Once you have the OCI cli installed we need to set up a configuration file to be used.
The default file is ~/.oci/config, but this location can be changed when using the command if you access multiple OCI installations.
This is the contents of my file.
1 2 3 4 5 6 7 | [DEFAULT] user=ocid1.user.oc1..oracle fingerprint=1e:6e:0e:79:38:f5:08:ee:7d:87:86:01:13:54:46:c6 key_file=/home/oracle/opc/oracle_private.pem tenancy=ocid1.tenancy.oc1..nobody region=us-phoenix-1 pass_phrase = oracle |
Now to walk through each line.
1. This identified the entry. Since the config file can contain entries for multiple OCI locations, this entry is identified as the default entry to use (If I don't specify one).
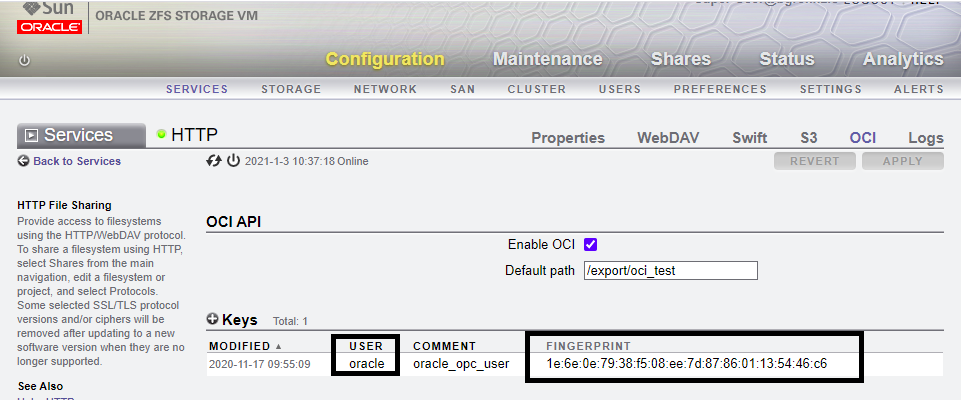
2. This is the user ID. Since I am using ZFS, the format is "ocid1.user.oc1..{zfs user}"
3. This is the fingerprint. I mentioned in the last blog post that this will be needed. This fingerprint identifies the API public_key entry on ZFS to use when matching the private API key being sent
4. This is the private key file. This contains the private API key that matches the public key that was added to the ZFS.
5. This is unimportant to ZFS, but is required to be set. Use the entry above.
6. Like #5. this is not used by ZFS but is needed by the OCI client.
7. This is optional. If the API private key was created with a pass_phrase, this the pass_phrase that matches the private key.
Create a bucket on OCI.
Almost there now ! We have everything in place for authentication, and we are ready to create an OCI bucket on ZFS for storing data.
The command is
oci os bucket create --endpoint {OCI object store location} --namespace-name {location on the object store} --compartment-id {compartment in OCI} --name {new bucket name}
Now let's walk through what the parameters will be for ZFS
--endpoint -> For my ZFS appliance, it is the url + oci
--namespace-name -> This is the share on the ZFS. "/export/short" in my config.
--compartment-id -> This is also the share on the ZFS. "/export/short" in my config.
--name -> the name of the bucket I want to create.
For my configuration below is the command and the output.. I now have a bucket created, and I am able upload data !
oci os bucket create --endpoint http://10.0.0.110/oci --namespace-name export/short --compartment-id export/short --name mynewbucket
{
"data": {
"approximate-count": null,
"approximate-size": null,
"compartment-id": "export/short",
"created-by": "oracle",
"defined-tags": null,
"etag": "a51c8ecbf1429f95b446c4413df9f494",
"freeform-tags": null,
"id": null,
"is-read-only": null,
"kms-key-id": null,
"metadata": null,
"name": "mynewbucket",
"namespace": "export/short",
"object-events-enabled": null,
"object-lifecycle-policy-etag": null,
"public-access-type": "NoPublicAccess",
"replication-enabled": null,
"storage-tier": "Standard",
"time-created": "2021-01-05T16:15:05+00:00",
"versioning": null
},
"etag": "a51c8ecbf1429f95b446c4413df9f494"
}
ADVANCED TOPIC -- SSL with OCI CLI
Now let's say I want to encrypt my connections to OCI and use the HTTPS server available on ZFS.
First I need to create a file containing the certificate. I can get the certificate by executing.
openssl s_client -showcerts -connect 10.0.0.110:443
This returns a lot of information, but within the output I can see the certificate, and I can copy and paste into a file.
Certificate chain
0 s:CN = 10.0.0.110, description = https://10.0.0.110:215/#cert
i:CN = 10.0.0.110, description = https://10.0.0.110:215/#cert
-----BEGIN CERTIFICATE-----
MIIDXDCCAkSgAwIBAgIIW+387wAAAAIwDQYJKoZIhvcNAQELBQAwPDETMBEGA1UE
AwwKMTAuMC4wLjExMDElMCMGA1UEDQwcaHR0cHM6Ly8xMC4wLjAuMTEwOjIxNS8j
Y2VydDAeFw0wNjAyMTUxODAwMDBaFw0zODAxMTkwMzE0MDdaMDwxEzARBgNVBAMM
CjEwLjAuMC4xMTAxJTAjBgNVBA0MHGh0dHBzOi8vMTAuMC4wLjExMDoyMTUvI2Nl
cnQwggEiMA0GCSqGSIb3DQEBAQUAA4IBDwAwggEKAoIBAQCyfgnTMtxgPEtrmCpB
J4gHngdqpRQWnUXA/OtWGymXME/+gAd5Q/8LZ74VpkHIwk3T7z/+tJVgL1HFmmbi
ZRSsXfSUgOBHm0doPn3VGbykz5MHWm3HHwjpPwvVhyeuVEkUfs/yiZ9B1WZrkr6U
ePNKlkbdL1VN5q2zuLdJ7+jn3HIiSS9j10i7HQVFEuzUAGdt3q0rp2MwaxSP6+cZ
hzMaI5IGBHuVkw2fGX1RdDB6uZpFEEhRSHURr5/3d+UgOprkMKp8Wph3kH0E2Nha
tGpSn2/6NM/Up/nDjfu2Dxm9A2aCwC56ShTckTTxE2HrgfSE9r/vEnkJEdSemH+X
9BuRAgMBAAGjYjBgMCYGCWCGSAGG+EIBDQQZFhdBdXRvbWF0aWNhbGx5IGdlbmVy
YXRlZDA2BgNVHREBAf8ELDAqggoxMC4wLjAuMTEwhwQKAABuhhZodHRwczovLzEw
LjAuMC4xMTA6MjE1MA0GCSqGSIb3DQEBCwUAA4IBAQAqxZk2knSBinWvTADkrvuS
C3vkeLyOLCRwABnGzZV80AAZ3tSVZt2JPXtg8uAVEj29J4VFw/I7HuneGL/faW9q
Qr9h+2WjvoT+m6lIfwELeaomZhkrLmJomGqSP1wfw5jaw3cpt0yOeS4RWUYb9eEe
bTH6laFBtSdbaI/uHslxpJwNRDwn8zBpAWmZk83UQ5CytH37yrFPRoHQWp+OqF+V
GYTPA4drxQ00nuelNfpHWMCjjMr0WxFz5rNJPMOAe2W1Xcr/MM1h04kGVwRtYsC0
4izqKtfiOHt0wMkSbYuSj1tIzdEzjVmxNSS7nv/znrMt+6SsdYQHMmaJ4+wHlJo4
-----END CERTIFICATE-----
---
Server certificate
subject=CN = 10.0.0.110, description = https://10.0.0.110:215/#cert
I want to copy the certificate including the "BEGIN CERTIFICATE" and "END CERTIFICATE" lines into a file.
I now need to set my environment to see the certificate file and use it. In my case "/home/oracle/opc/wallet_cloud/zfs.cer"
export REQUESTS_CA_BUNDLE=/home/oracle/opc/wallet_cloud/zfs.cer
I can now view the buckets in my object store, and upload files encrypted.
oci os bucket list --endpoint https://10.0.0.110/oci --namespace-name export/short --compartment-id export/short
{
"data": [
{
"compartment-id": "export/short",
"created-by": "oracle",
"defined-tags": null,
"etag": "a51c8ecbf1429f95b446c4413df9f494",
"freeform-tags": null,
"name": "mynewbucket",
"namespace": "export/short",
"time-created": "2021-01-05T16:15:05+00:00"
}
]
}
The OCI documentation should give you everything you need to upload/download objects within a bucket.