Object Retention Rules is one of the new features that was released in ZFSSA version 8.8.36. Before I talk about Object Retention Rules on buckets on ZFSSA, I am going to go how to leverage the new access control polies that go along with managing objects, buckets, and retention.
User Architecture
If you have followed my previous postings on
configuring ZFS as object store, you found that one of the options available is to configure ZFSSA as an OCI Gen 2 (sometimes called OCI native) object store.
When configuring this API interface on ZFSSA, the authentication utilizes the same public/private key concept that is used in most of the Oracle Cloud.
If you want to read my post on configuring authentication you can find it
here.
What I want to go through in this post is how you can configure a set of user roles on ZFSSA with different permissions based public/private keys.
This will help you isolate and secure backups that were sent from multiple sources, and allow you to define both a security administrator (to apply retention policies), and an auditor to view the existence of backups without having the ability to delete or update backups.
In the "User Architecture" diagram at the beginning of this post you see that I have defined 5 user roles that will be used to manage the object store security for the backups.
Users:
- SECADMIN - This user role is the security administrator for all 3 object store backups, and all three buckets. This user role is responsible for creating, deleting and assigning retention rules to the buckets.
- AUDITOR - This user reviews the backups and has a read only view of all 3 backups. The auditor cannot delete or update any objects, but they can view the existence of the backup pieces.
- GLUSER - This user controls the backups for GLDB only
- APUSER - This user controls the backups for APDB only
- DWUSER - This user controls the backups for DWDB only
NOTE: Because the Object Store API controls the access to objects in the bucket, all access to objects in a bucket is through the bucket owner. I can have multiple buckets on the same share, managed by different different users, but access WITHIN the bucket is only granted to the bucket owner.
Based on the above note, I am going to create 3 users to manage the buckets for the 3 database backups.
The 2 additional user roles, SECADMIN and AUDITOR are going to control their access through the use of RSA keys.
Because I am not going to use pre-authenticated URLs for my backups (which requires login), all 3 users are going to be created as "no-login" users. Below is an example of creating the APUSER.
I created all 3 users as no-login users
Project/Share for Object Storage
Now I am going to create a project and share to store the backup pieces for all 3 databases. The project is going to be "dbbackups" and the share is going to be "dbbackups". I am going to set the default user for the share to "oracle" and I am also going to grant the other 3 users "Full Control" of the share. I will later limit the permissions for these users.
Share User Access
User certificates:
Authentication to the object store is through the use of RSA public/private certificates.
For each user/role I created a certificate that will be used for authentication.
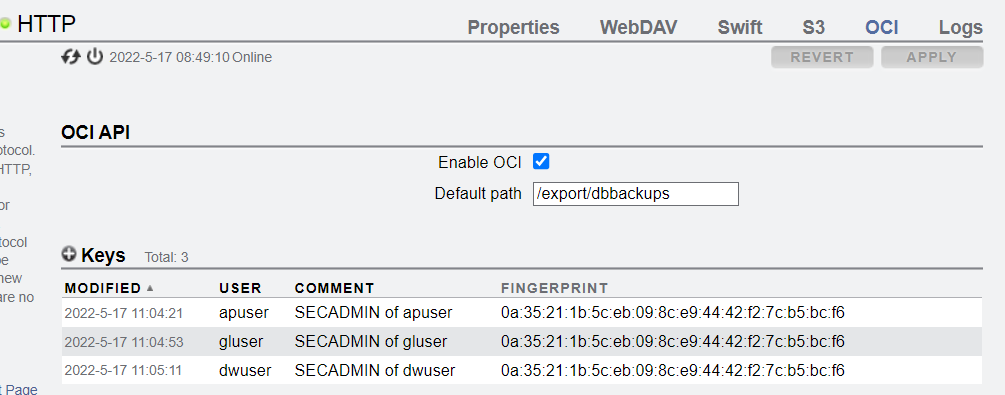
The following table shows the users/roles and the fingerprint that identifies them.
Authentication:
Within the OCI service on the ZFSSA I combine the user and key (fingerprint) to provide the role.
First I will add the SECADMIN role. Notice that I am adding this users access to all 3 database backup "users". This will allow the SECADMIN role to manage bucket creation/deletion and retention to the individual buckets. The role SECADMIN is accessed through the key.
I will start by adding the key owned by this role (SECADMIN) to the 3 users APUSER, GLUSER and DWUSER.
Now that I have the SECADMIN role assigned to the 3 users, I want set the proper capabilities for this role. I click on the pencil to edit the key configuration, and I can see the permissions assigned to this user/key combination. I want to allow the SECADMIN the ability create buckets, delete buckets and to control the retention within the 3 users buckets. This role will need the ability to read the bucket. Notice that this role does not have ability to read any of the objects within the bucket
Now I am going to move on to the AUDITOR role. This role will be configured using the AUDITOR key assigned to all 3 users. Within each user the AUDITOR will be granted the ability to read the bucket and the objects but not make any changes.
I now have both the SECADMIN role and the AUDITOR role defined for all 3 users. Below is what is configured within the OCI service. Notice that that there are 2 keys set for each user, and the there are 2 unique keys (one for SECADMIN and one for AUDITOR).
Finally I am going to add the 3 users that own the buckets and grant them access to create objects, but not control the retention or be able to add/remove buckets.
Once completed with adding users/keys I have my 2 roles defined and assigned to each user, and I have an individual key for each user/backup.
When completed, the chart below shows the permissions for each user/role.
OCI cli configuration :
I added entries to the ~/.oci/config file for each of the users/roles configured for the service.
Below is an example entry for the SECADMIN role with the APDB bucket.
[SECADMIN_APDB]
user=ocid1.user.oc1..apuser
fingerprint=0a:35:21:1b:5c:eb:09:8c:e9:44:42:f2:7c:b5:bc:f6
key_file=~/keys/secadmin.ppk
tenancy=ocid1.tenancy.oc1..nobody
region=us-phoenix-1
endpoint=http://150.136.215.19
os.object.bucket-name=apdb
namespace-name=dbbackups
compartment-id=dbbackups
Below is a table of the entries that I added to the config file.
Creating buckets:
Now I am going to create my 3 buckets using the SECADMIN role. Below is an example of adding the bucket for APDB
[oracle@oracle-19c-test-tde keys]$ oci os bucket create --namespace-name dbbackups --endpoint http://150.136.215.19 --config-file ~/.oci/config --profile SECADMIN_APDB --name apdb --compartment-id dbbackups
{
"data": {
"approximate-count": null,
"approximate-size": null,
"auto-tiering": null,
"compartment-id": "dbbackups",
"created-by": "apuser",
"defined-tags": null,
"etag": "2f0b55dbbb925ebbaabbc37e3ce342fa",
"freeform-tags": null,
"id": "2f0b55dbbb925ebbaabbc37e3ce342fa",
"is-read-only": null,
"kms-key-id": null,
"metadata": null,
"name": "apdb",
"namespace": "dbbackups",
"object-events-enabled": null,
"object-lifecycle-policy-etag": null,
"public-access-type": "NoPublicAccess",
"replication-enabled": null,
"storage-tier": "Standard",
"time-created": "2022-05-17T17:55:49+00:00",
"versioning": "Disabled"
},
"etag": "2f0b55dbbb925ebbaabbc37e3ce342fa"
}
I then did the same thing for the GLDB bucket using SECADMIN_GLDB, and the DWDB bucket using SECADMIN_DWDB.
Once the buckets were created, I attempted to create buckets with both the AUDITOR role, and the DB role. You can see below that both of these configurations did not have the correct privileges.
[oracle@oracle-19c-test-tde keys]$ oci os bucket create --namespace-name dbbackups --endpoint http://150.136.215.19 --config-file ~/.oci/config --profile AUDITOR_APDB --name apdb --compartment-id dbbackups
ServiceError:
{
"code": "BucketNotFound",
"message": "Either the bucket does not exist in the namespace or you are not authorized to access it",
"opc-request-id": "tx3a37f1dee0cc4778a1201-006283e2a1",
"status": 404
}
[oracle@oracle-19c-test-tde keys]$ oci os bucket create --namespace-name dbbackups --endpoint http://150.136.215.19 --config-file ~/.oci/config --profile APDB --name apdb --compartment-id dbbackups
ServiceError:
{
"code": "BucketNotFound",
"message": "Either the bucket does not exist in the namespace or you are not authorized to access it",
"opc-request-id": "tx46435ae6b8234982b3fbd-006283e2a9",
"status": 404
}
Listing buckets:
All of the entries I created have access to view the buckets. Below is an example of SECADMIN_APDB listing buckets. You can see that I have 3 buckets each owned by the correct user.
[oracle@oracle-19c-test-tde keys]$ oci os bucket list --namespace-name dbbackups --endpoint http://150.136.215.19 --config-file ~/.oci/config --profile SECADMIN_APDB --compartment-id dbbackups
{
"data": [
{
"compartment-id": "dbbackups",
"created-by": "apuser",
"defined-tags": null,
"etag": "2f0b55dbbb925ebbaabbc37e3ce342fa",
"freeform-tags": null,
"name": "apdb",
"namespace": "dbbackups",
"time-created": "2022-05-17T17:55:49+00:00"
},
{
"compartment-id": "dbbackups",
"created-by": "dwuser",
"defined-tags": null,
"etag": "866ded83e5ea2a29c66dca0d01036f0e",
"freeform-tags": null,
"name": "dwdb",
"namespace": "dbbackups",
"time-created": "2022-05-17T17:58:32+00:00"
},
{
"compartment-id": "dbbackups",
"created-by": "gluser",
"defined-tags": null,
"etag": "2169cf94f86009f66ca8770c1c58febb",
"freeform-tags": null,
"name": "gldb",
"namespace": "dbbackups",
"time-created": "2022-05-17T17:58:17+00:00"
}
]
}
Configuration retention lock :
Here is the documentation on how to configure retention lock for the objects within a bucket. For my example, I am going to lock all objects for 15 days. I am going to use the SECADMIN_APDB account to lock the objects on the apdb bucket.
[oracle@oracle-19c-test-tde keys]$ oci os retention-rule create --endpoint http://150.136.215.19 --namespace-name dbbackups --config-file ~/.oci/config --profile SECADMIN_APDB --bucket-name apdb --time-amount 30 --time-unit days --display-name APDB-30-day-Bound-backups
{
"data": {
"display-name": "APDB-30-day-Bound-backups",
"duration": {
"time-amount": 30,
"time-unit": "DAYS"
},
"etag": "2c9ab8ff9c4743392d308365d9f72e05",
"id": "2c9ab8ff9c4743392d308365d9f72e05",
"time-created": "2022-05-17T18:49:24+00:00",
"time-modified": "2022-05-17T18:49:24+00:00",
"time-rule-locked": null
}
}
Now I am going to make sure my AUDITOR role and my BACKUP role do not have privileges to manage retention. For both of these I can an error.
[oracle@oracle-19c-test-tde keys]$ oci os retention-rule create --endpoint http://150.136.215.19 --namespace-name dbbackups --config-file ~/.oci/config --profile AUDITOR_GLDB --bucket-name gldb --time-amount 30 --time-unit days --display-name APDB-30-day-Bound-backups
ServiceError:
{
"code": "BucketNotFound",
"message": "Either the bucket does not exist in the namespace or you are not authorized to access it",
"opc-request-id": "tx52e8849aa6444c639d59b-006283ee99",
"status": 404
}
I set the retention rule for the other buckets, and now I can use the AUDITOR accounts to list the retention rules.
[oracle@oracle-19c-test-tde keys]$ oci os retention-rule list --endpoint http://150.136.215.19 --namespace-name dbbackups --config-file ~/.oci/config --profile AUDITOR_APDB --bucket-name apdb
oci os retention-rule list --endpoint http://150.136.215.19 --namespace-name dbbackups --config-file ~/.oci/config --profile AUDITOR_GLDB --bucket-name gldb
oci os retention-rule list --endpoint http://150.136.215.19 --namespace-name dbbackups --config-file ~/.oci/config --profile AUDITOR_DWDB --bucket-name dwdb
{
"data": {
"items": [
{
"display-name": "APDB-30-day-Bound-backups",
"duration": {
"time-amount": 30,
"time-unit": "DAYS"
},
"etag": "2c9ab8ff9c4743392d308365d9f72e05",
"id": "2c9ab8ff9c4743392d308365d9f72e05",
"time-created": "2022-05-17T18:49:24+00:00",
"time-modified": "2022-05-17T18:49:24+00:00",
"time-rule-locked": null
}
]
}
}
[oracle@oracle-19c-test-tde keys]$ oci os retention-rule list --endpoint http://150.136.215.19 --namespace-name dbbackups --config-file ~/.oci/config --profile AUDITOR_GLDB --bucket-name gldb
{
"data": {
"items": [
{
"display-name": "GLDB-30-day-Bound-backups",
"duration": {
"time-amount": 30,
"time-unit": "DAYS"
},
"etag": "ee0d6114310a9971f5a464b428916e48",
"id": "ee0d6114310a9971f5a464b428916e48",
"time-created": "2022-05-17T18:56:45+00:00",
"time-modified": "2022-05-17T18:56:45+00:00",
"time-rule-locked": null
}
]
}
}
[oracle@oracle-19c-test-tde keys]$ oci os retention-rule list --endpoint http://150.136.215.19 --namespace-name dbbackups --config-file ~/.oci/config --profile AUDITOR_DWDB --bucket-name dwdb
{
"data": {
"items": [
{
"display-name": "DWDB-30-day-Bound-backups",
"duration": {
"time-amount": 30,
"time-unit": "DAYS"
},
"etag": "96cc109a7308d5f849541be72d87757a",
"id": "96cc109a7308d5f849541be72d87757a",
"time-created": "2022-05-17T18:57:42+00:00",
"time-modified": "2022-05-17T18:57:42+00:00",
"time-rule-locked": null
}
]
}
}
Sending backups to buckets :
Here is the link to the "archive to cloud" section of the latest ZDLRA documentation. The buckets are added as cloud locations. Since I am going to be using an immutable bucket, I also need to add a metadata bucket to match the normal backup bucket. The metadata bucket holds temporary objects that get removed as the backup is written.
I created 3 additional buckets, "apdb_meta", "gldb_meta" and "dwdb_meta".
When I configure the Cloud Location I want to use the keys I created to send the backups.
The backup pieces were sent by the keys for apuser, gluser, and dwuser.
I used the process in the documentation to send the backups pieces from the ZDLRA
Audit Backups :
Now that I have backups created for my database, I am going to use the the AUDITOR role to report on what's available within the apdb bucket.
First I am going to look at the Retention Settings.
[oracle@oracle-19c-test-tde keys]$ oci os retention-rule list --endpoint http://150.136.215.19 --namespace-name dbbackups --config-file ~/.oci/config --profile AUDITOR_APDB --bucket-name apdb
{
"data": {
"items": [
{
"display-name": "APDB-30-day-Bound-backups",
"duration": {
"time-amount": 30,
"time-unit": "DAYS"
},
"etag": "2c9ab8ff9c4743392d308365d9f72e05",
"id": "2c9ab8ff9c4743392d308365d9f72e05",
"time-created": "2022-05-17T18:49:24+00:00",
"time-modified": "2022-05-17T18:49:24+00:00",
"time-rule-locked": null
}
]
}
}
Now I am going to print out all the backups that exist for the APDB database.
I am using the python script that comes with the Cloud Backup Library and instructions for how to use it can be found in my blog
here.
Below I am running the script. Notice I am running it using the AUDITOR role.
[oracle@oracle-19c-test-tde ~]$ python2 /home/oracle/ociconfig/lib/odbsrmt.py --mode report --ocitype bmc --host http://150.136.215.19 --dir /home/oracle/keys/reports --base apdbreport --pvtkeyfile /home/oracle/keys/auditor.ppk --pubfingerprint a8:31:78:c2:b4:4f:44:93:bd:4f:f1:72:1c:37:c8:86 --tocid ocid1.tenancy.oc1..nobody --uocid ocid1.user.oc1..apuser --container apdb --dbid 2867715978
odbsrmt.py: ALL outputs will be written to [/home/oracle/keys/reports/apdbreport12193.lst]
odbsrmt.py: Processing container apdb...
cloud_slave_processors: Thread Thread_0 starting to download metadata XML files...
cloud_slave_processors: Thread Thread_0 successfully done
odbsrmt.py: ALL outputs have been written to [/home/oracle/keys/reports/apdbreport12193.lst]
And finally I can see the report that is creating from this script.
FileName
Container Dbname Dbid FileSize LastModified BackupType Incremental Compressed Encrypted
870toeq3_263_1_1
apdb ORCLCDB 2867715978 1285029888 2022-05-17 19:09:45 Datafile true false true
890toetk_265_1_1
apdb ORCLCDB 2867715978 2217476096 2022-05-17 19:12:17 ArchivedLog false false true
8a0tof0j_266_1_1
apdb ORCLCDB 2867715978 2790260736 2022-05-17 19:14:15 Datafile true false true
8b0tof4g_267_1_1
apdb ORCLCDB 2867715978 2124677120 2022-05-17 19:15:52 Datafile true false true
8c0tof7f_268_1_1
apdb ORCLCDB 2867715978 536346624 2022-05-17 19:16:21 Datafile true false true
8d0tof89_269_1_1
apdb ORCLCDB 2867715978 262144 2022-05-17 19:16:25 ArchivedLog false false true
c-2867715978-20220517-00
apdb ORCLCDB 2867715978 18874368 2022-05-17 19:09:47 ControlFile SPFILE false false true
c-2867715978-20220517-01
apdb ORCLCDB 2867715978 18874368 2022-05-17 19:16:26 ControlFile SPFILE false false true
Total Storage: 8.37 GB
Conclusion :
By creating 3 different roles for the user through the use of separate keys I am able to provide a separation of duties on the OCI object store.,
SECADMIN - This user role creates/deletes buckets and controls retention. This user role cannot see any backup pieces, and this user role cannot delete any objects from the buckets. This user role is isolated from the backup pieces themselves.
AUDITOR - This user role is used to create reporting on the backups to ensure there are backup pieces available.
DBA - These user roles are used to manage the individual backup pieces within the bucket but they do not have the ability to delete the bucket, or change the retention.
This provides a true separation of duties.