ZFS can be configured to use Oracle Key Vault (OKV) as a KMIPs cluster to store it's encryption keys. In this blog post I will go through how to configure my ZFS replication pair to utilize my OKV cluster and take advantage of the Raw Crypto Replication mode introduced in 8.8.57.
OKV Cluster Environment:
First I am going to describe the environment I am using for my OKV cluster.
I have 2 OKV servers, OKVEAST1 ( IP:10.0.4.230) and OKVEAST2 (IP: 10.0.4.254). These OKV servers are both running 21.6 (the current release as of writing this post).
ZFS replication Pair:
For my ZFS pair, I am using a pair of ZFS hosts that I have been running for awhile. My first ZFS host is "testcost-a" (IP: 10.0.4.45) and my second ZFS host is "zfs_s3"( IP: 10.0.4.206). Both of these servers are running the 8.8.60 release.
For my replication, I already have "testcost-a" configured as my upstream, and "zfs_s3" configured as the downstream.
Steps to configure encryption using OKV
Documentation:
The documentation I am using to configure ZFS can be found in the 8.8.x Storage Administrators guide. I did look through the documentation for OKV, and I didn't find anything specific that needs to be done when using OKV as a KMIP server.
Step #1 - Configure endpoints/wallets in OKV
The first step is to create 2 endpoints in OKV and assign a shared wallet between these 2 endpoints.
I am starting by creating a single wallet that I am going to use share the encryption keys between my 2 ZFS replication pairs. I
The next step after creating the wallet is to create the 2 endpoints. Each ZFS host is an endpoint. Below is the screenshot for adding the first node.
After creating both endpoints I see them in the OKV console.
Then I click on each endpoint and ensure that
- The default wallet for each endpoint is the "ZFS_ENCRYPTION_KEYS" wallet
- The endpoint has the ability to manage this wallet.
Then I go back to endpoint list in the console and save the "enrollment token" for each node and logout.
Server Enrollment Token
ZFS_S3 FdqkaimSpCUBfVqV
TESTCOST-A uy59ercFNjBisU12
I then go to the main screen for OKV and click on the enrollment token download
Enter the Enrollment Token and click on "Submit Token"
You see that the token is validated. Then click on Enroll and it will download the token "okvclient.jar" which I am renaming to okvclient_{zfs server}.zip. This will allow me to extract the certificates.
When completed, I have enrolled the endpoints and I am ready to add them to the ZFS.
Step #2 - Add the Certificates
When I look at the .jar files that were created for the endpoints I can see all the files that are included in the endpoint enrollment. I need to add the certificates to the ZFS servers. I can find those in the "ssl" directory contained in .jar file.
I start by uploading the "key.pem" for my first ZFS "testcost-a" in the Configuration=>SETTINGS=>Certificates=>System section of the BUI.
After uploading it I then add the "cert.pem" certificate in system also.
After uploading, I clicked in the pencil to see the details for the certificate.
NOTE: The IP Address is the primary node in my OKV cluster.
Under Certificates=>Trusted I uploaded the CA.pem certificate.
After uploading this certificate, I click on the pencil and select "kmip" identifying this certificate to be used for the KMIP service.
The certificate should now appear as a trusted KMIP services certificate.
I can now upload the certificates for my other ZFS server (zfs_s3) the same way.
Step #3 - Add the OKV/KMIP service
I now navigate to the Shares=>ENCRYPTION=>KMIP section of the BUI to add the KMIP servers to my first ZFS host. Because I have 2 possible KMIP servers (I am using an OKV cluster), I am going to uncheck the "Match Hostname against certificate subject" button. I left the default to destroy the key when removing it from the ZFS.
I added the 2 OKV servers (if I had a more than 2 nodes in my cluster I would add those nodes also). I added the port used for KMIP services on OKV (5696), and I chose the "Client TLS Authentication Certificate" I uploaded in the previous step (FLxULFbeMO).
I perform the same process on my second ZFS so that the paired ZFS servers are all configured to communicate with my OKV cluster to provide KMIP services.
NOTE: If you want to get the list of OKV hosts in the cluster you can look in the .jar file within the conf=>install.cfg file to see the OKV servers details. Below is the contents of my file.
Once I add the KMIP configuration to both of my ZFS servers I can look at my endpoints in OKV and see that they are both ENROLLED, and that OKV knows the IP address of my ZFS servers.
Step #4 - Add one or more keys.
On my upstream ZFS, I click on the "+" to add a new key and save it.
After adding it, the key appears in this section.
Step #5 - Add the keys to the shared wallet
I noticed that even though the wallet is the default wallet for the endpoints, the key did not get added to the wallet. I can see that both nodes have access to manage the wallet.
I clicked on the wallet, and then the "Add Contents", from there I am adding my new key to the wallet.
And now I login into the second ZFS (zfs_s3) and add the same key. Make sure you add the same named key on the second ZFS so that they can match.
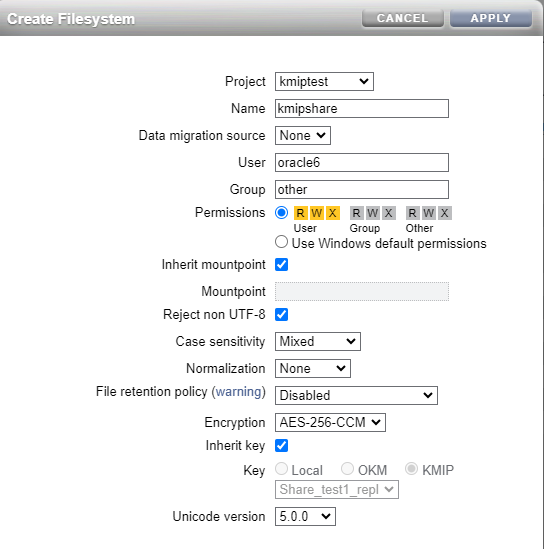
Step #6 - Create a new encrypted project/share
On my first ZFS (upstream - testcost-a) I am creating a new project and share that is encrypted using the key from the KMIP service.
Then within the share, I configure replication to my paired ZFS.
And now I am creating a share within this project.
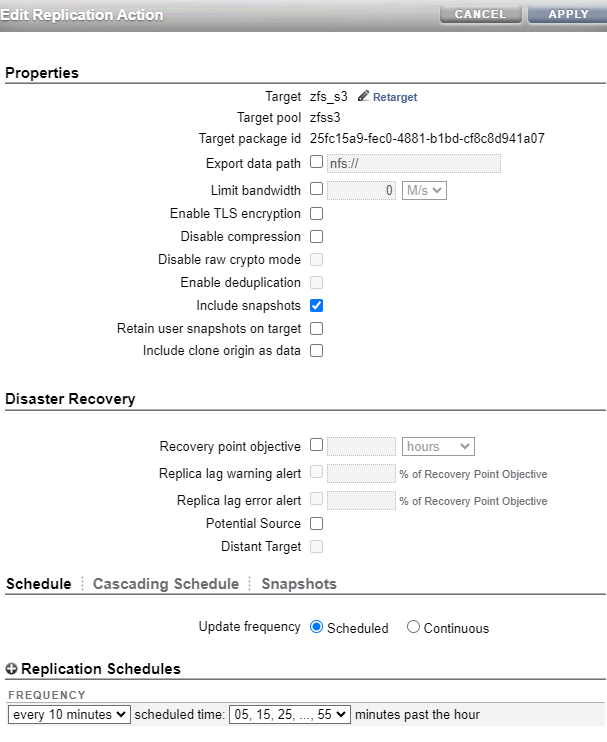
Step #7 - Configure replication
Finally I configured replication from my project in my upstream (testcost-a) to my downstream (zfs_s3). Below are the settings for my replication processing to send a snapshot every 10 minutes. Notice that I made sure that I did NOT disable raw Crypto Mode (which is what I am using for this replication). You can follow
this link to learn more about Raw Crypto Replication.
Result:
I now have replication on my encrypted share working between my upstream and downstream. With this new feature, the blocks are sent in their original encrypted format, and are stored on the downstream encrypted. Since both ZFS servers can access the encryption key, both servers are able to decrypt the blocks.
I did test shutting down one of my OKV hosts, and found that the ZFS severs were able to successfully connect to the surviving node.
I even mounted the share, stored some files, replicated it, mounted a snapshot copy, and ensured that both ZFS servers presented the shares readable.